When you're deciding on the structure of project patterns for a new process, often the first thing to consider is how to represent the different hierarchies of elements that make up projects.
In FDD for example there is the hierarchy of features, normally described as being Features, which are contained in Feature Sets, which are contained in Business Areas or Major Feature Sets. This logical grouping of functionality is independent of priority and time-ordering. It may well correspond to the structure of the user manual for example or the Functional Specification should such a document be required. It doesn't give us any time view. On the other hand the hierarchy from Releases -> containing Timeboxes -> containing Features is a time-based structure. Similarly the hierarchy based on the five subprocesses of FDD also will have a time correspondence: The Definition Stage -> containing FDD#1 Develop Overall Model, FDD#2 Build Feature List, and FDD#3 Plan by Feature; The Build Stage -> containing many instances (for each feature) of FDD#4 Design by Feature and FDD#5 Build by Feature; and the Release/Deployment Stage following completion of a release.
Each of these hierachies is an important view of the tasks and artifacts in the project. However when defining a process in xProcess you must decide which hierarchy will define where a task "lives". This is the parent-child hierarchy of tasks and is analogous to a directory structure which tells you where a file is located. All the other relevant hierachies can be represented with Folders which contain explicit or implicit (defined by rule) references to the tasks. This means that different features may appear in different Timeboxes and Releases, and indeed different subtasks of a feature may appear in different folders (design and build for example may appear in different timeboxes; build and certify a feature may appear in different stages). Since Folders may contain Folders in xProcess as many hierarchies can be provided as are required to understand the process, each to several containment layers if this helps understand the view.
So Folders provide an alternative hierarchy of tasks to the main parent-child structure. Their membership is defined either explicitly (because the process has put them there or the user has dragged them into the Folder) or implicitly (because the task has a matching category to the category of the Folder). In some methods it is sensible to use the parent-child hierarchy for time-based structure (Basic Scrum 3.0.1 follows this scheme for example). In others using a more static structure such as Business Areas/Feature Sets in FDD or a Work Breakdown Structure in traditional methods, gives the preferred structure for parents-children with more dynamic hierachies being represented with Folders.
Subscribe to:
Post Comments (Atom)
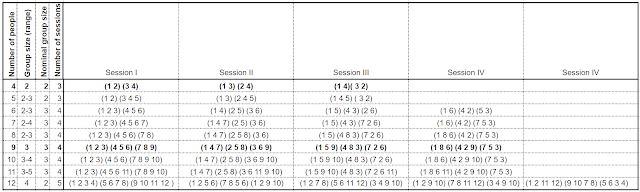
Breakout sessions that ensure everyone in the meeting meets everyone else
Lockdown finds us doing more and more in online meetings, whether it's business, training, parties or families. It also finds us spendin...
-
 Understanding Cost of Delay (Part 2): Delay Cost and Urgency Profiles In part one of this series of blogs on Understanding Cost of Dela...
Understanding Cost of Delay (Part 2): Delay Cost and Urgency Profiles In part one of this series of blogs on Understanding Cost of Dela... -
 When starting to use xProcess there are a number of terms that may be unfamiliar. What for example is an "overhead" task? In gener...
When starting to use xProcess there are a number of terms that may be unfamiliar. What for example is an "overhead" task? In gener... -
 Cost of Delay (CoD) is a vital concept to understand in product development. It should be a guide to the ordering of work items, even if - ...
Cost of Delay (CoD) is a vital concept to understand in product development. It should be a guide to the ordering of work items, even if - ...
No comments:
Post a Comment