http://sourceforge.net/apps/mediawiki/xprocess/index.php?title=Reporting (the Recursive Solution). Existing actions can still be used but those that have a tendency to generate large amounts of data may need to be rewritten in order to get the benefit of the new mechanism.
The following example reworks the Work Log for Person action.
In which ever Process you want to, create a new Action called 'Get DailyRecords for Person'. This will return a set of daily records in a date range and is the FetchSet Action.
The first difference we see in v3.5 is that there is a new Editor for Actions. The Editor is split into three tabs:
- Editor tab – a text area for the OGNL Expression
- Details Tab:

- Action Name - the name of the action
- Applicable to - What it is applicable to (any element is the default)
- UI Action - should it appear on context menu for element its applicable to?
- On this tab are a further two tabs; Parameters: add the Parameters that will be presented to the user when the Action is run. These parameter values are sent into the OGNL expression when run. We will come onto the Export tab later.
- Test Action Tab:

- On the Test Action Tab you can choose an Element to run the Action on to test it and enter the parameters for that action. It is recommended that you create test Elements for this, as the Action may change that Elements data.
- The lower part of this tab shows the output when the test it run
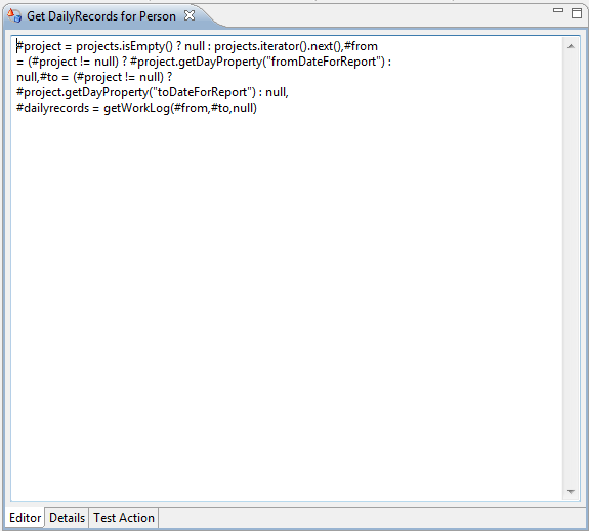
For the 'Get DailyRecords for Person' we just need the OGNL for retrieving the daily records, so in the Actions Editor we enter in:
#project = projects.isEmpty() ? null : projects.iterator().next(),#from= (#project != null) ? #project.getDayProperty("fromDateForReport") :null,#to = (#project != null) ?#project.getDayProperty("toDateForReport") : null,#dailyrecords = getWorkLog(#from,#to,null)
Hit Ctrl+S to save the Action.
The next Action to create is the 'Generate Work Log Details'. This Action is the Subordinate Action. You can have one or more Subordinate Actions, and these Actions are run against the data set that the FetchSet Action returns. The OGNL to enter in this Actions Editor is:
#output = '"' +day + '","' +assignment.task.project.label + '","' +assignment.task.label + '","' +assignment.requiredResource.roleType.label + '","' +time/60.0 + '","' +logEntry + '","' +confirmed + '"',#output = #output + '\n',#output
Hit Ctrl+S to save the Action.
The final Action is the 'New Work Log for Person'. It's OGNL gets called before the FetchSet and Subordinate Actions, so we use that to provide the column header that will be written to file:
#project = projects.isEmpty() ? null : projects.iterator().next(),#from= (#project != null) ? #project.getDayProperty("fromDateForReport") :null,#to = (#project != null) ?#project.getDayProperty("toDateForReport") : null,#output = 'Work Log for: ' + label + '\n'+ 'From: ' + ((#from==null) ? 'earliest booked time in data source': #andfrom) + ' To: ' + ((#to==null) ? #$today : #to) +'\n'+ 'Date,Project,Task,Role,Hours,Log Entry,Confirmed\n',#output
Then go to the Details tab and:
- Make the Action applicable to Person
- Click on the Export tab and tick the Export Action checkbox. Give it a .csv extension
- On the FetchSet Field click on the '…' and select the ' Get DailyRecords for Person' Action
- Now click on the Add button in the Subordinate section, and select the ' Generate Work Log Details' Action
- Hit Ctrl+S to save the Action
We can now test the Action via File | Export | xProcess Export | Custom Reports. When the Action runs it uses the FetchSet Action to retrieve a set of Daily Records on Projects for the selected Person. This Daily Record set is then iterated over passing in the Daily Records to the Subordinate Action.
Since each time a Daily Record is iterated over a line is written out to file, it prevents the building up of large data to be written out to file, and possible memory issues.