Lockdown finds us doing more and more in online meetings, whether it's business, training, parties or families. It also finds us spending inordinate amounts of time on trivail and time-consuming tasks of dubious value. This blog explores exactly such a problem!
I recently wanted to find a way to divide an online meeting into several breakout sessions, ensuring at the end of them, everyone would have met everyone else. But how many sessions of what size would I need, and how could I put the right people in the right group in each session?
After a brief internet search which didn't answer my question (I know someone's done this before, and probably written about how to do it, but I didn't find them!) I decided to work it out myself. Here's my attempt for groups of between 4 and 12 - minimising the number of breakout sessions, the number of people that meet people twice, and variation in group size.
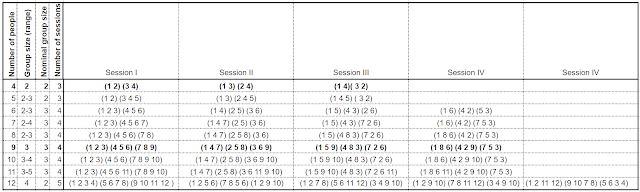
Let me know if you're keen to extend this to larger groups.
Some further thoughts on approaching this problem
Let's start simply. If I had 4 people, I could easily put them in 2 groups of 2 people. I'll number the people from 1 to 4, so here's my first session...
Session A: (1,2) (3,4) ... start at 1 and add 1 each time
Everyone's now met one person. Since they meet 1 person in each session, and there are 3 other people to meet, I need 2 more sessions:
Session B: (1,3) (2,4) ... start at 1 and then 2, adding 2
Session C: (1,4) (3,2) ... start at 1 and add 3 (mod 4) each time
It turns out I can do this with any even number of people, put into n groups of 2 people*. After the correct (2n - 1) sessions, they all have met everyone. Here's a solution for 8 people for example, with 7 sessions, each with 4 groups of 2):
Session A: (1,2) (3,4) (5,6) (7,8) ... start at 1 and add 1 each time
Session B: (1,3) (5,7) (2,4) (6.8) ... start at 1 and then 2, adding 2 each time
Session C: (1,4) (7.2) (5,8) (3,6) ... start at 1 and add 3 (mod 8) each time
Session D: (1,5) (2,6) (3,7) (4,8) ... start at 1,2,3, and 4, adding 4 each time
Session E: (1,6) (3,8) (5,2) (7,4) ... start at 1 and add 5 each time
Session F: (1,7) (5,3) (2,8) (6,4) ... start at 1 and then 2, adding 6 each time
Session G: (1,8) (7,6) (5,4) (3,2) ... start at 1 and add 7 each time
These get more laborious to work out with larger numbers, but anyway there are too many sessions when there are a lot of people; better to have larger groups with fewer sessions.
For groups of 3, you need at least 9 people**. 9 people can meet everyone else in 4 sessions with groups of 3 (there are 8 others to meet, and you meet 2 in each session).
Session A: (1,2,3) (4.5.6) (7,8,9) ... start at 1 and add 1 each time
Session B: (1,4,7) (5,8,2) (9,6,3) ... start at 1,5 and 3, adding 3 (mod 9) each time
Session C: (1,5,9) (4,8,3) (7,2,6) ... start at 1 and add 4 each time
Session D: (1,8,6) (4,2,9) (7,5,3) ... start at 1 and add 7 each time (adding 5 clashes wih group A, adding 6 clashes wih group B)
The next feasible number with groups of 3 (where nobody meets the same person twice) is 15. That's 5 groups of 3 for 7 sessions.
The next square number, 16, divided into 4 groups of 4 can be designed so everyone meets everyone else in 5 sessions. These two problems are left as an exercise for the reader!
(Send me your workings when complete. :-)
Notes:
* You can design groups of size n where people meet once and only once provided the number of people N is divisible by n, and (N-1) is divisible by (n-1). That is all even numbers for groups of 2, all odd multiples of 3 for groups of 3, etc. (Note: If n is the number in the groups, we need the number of people, N, to be divisible by n so there's an equal number in each group, but in addition we need (N-1) to be divisible by (n-1) so we have a whole number of sessions.
** It turns out n squared is the minimum meeting size with n people in each breakout group, in order to meet everybody once and only once.





{kind=link}
{kind=link}