My number one favourite? Not estimating them at all!
Instead, ensure stories do not exceed an agreed size that ensures they fit easily within a sprint (ok - I agree that's estimating, but it's much simpler estimating than tee-shirt sizes (S, M. L or/and too big) or points (1, 2, 3, 5, 8, and too big). Then spend the time you've saved estimating the size of stories on estimating the number of stories in the various epics in your product backlog. Measure velocity in stories not points (or use only two sizes: 1 point and too big) and forecast the completion of epics and minimum-marketable-features based on the throughput of stories (velocity) and the number of stories.
As well as saving a ton of time, it turns out your forecasting will be just as accurate as if you'd spent ages agonizing over each story! See for example +Vasco Duarte's blog about the evidence for improved forecasts from this approach.
The key question - as +Neil Killick points out in his recent "People Need Estimates" - is what problem are we trying to solve with our estimating?
I was working with a team recently who were concerned that they had missed their forecast for the second sprint in a row. The retrospective meeting came up with several suggestions about how they could improve their forecast for the next sprint. I asked the team whether there was anyone (outside the team themselves) who was interested or concerned about their forecasting ability. The last few sprints were running at a throughput that was over double the average for the previous year. If the team continued to focus on the improvements they were making, the business could easily adjust to this higher efficiency. The business did not need (or probably believe) the over-optimistic forecasts that the team were making. Shown the evidence of actually completed work, the business will adjust to the new opportunities the improvements open up.
Subscribe to:
Post Comments (Atom)
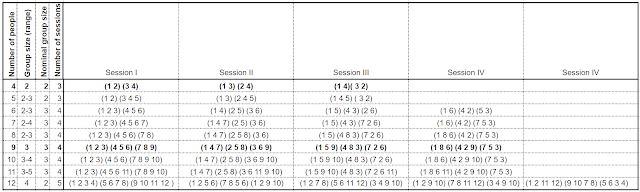
Breakout sessions that ensure everyone in the meeting meets everyone else
Lockdown finds us doing more and more in online meetings, whether it's business, training, parties or families. It also finds us spendin...
-
 When starting to use xProcess there are a number of terms that may be unfamiliar. What for example is an "overhead" task? In gener...
When starting to use xProcess there are a number of terms that may be unfamiliar. What for example is an "overhead" task? In gener... -
 Cost of Delay (CoD) is a vital concept to understand in product development. It should be a guide to the ordering of work items, even if - ...
Cost of Delay (CoD) is a vital concept to understand in product development. It should be a guide to the ordering of work items, even if - ... -
Ron Lichty is well known in the Software Engineering community on the West Coast as a practitioner, as a seasoned project manager of many su...
No comments:
Post a Comment